Menü
Digitalisierte Jahrgänge
1845
1846
1847
1848
1849
1850
Kontakt:
Heinz Rosenkranz MSc
Parndorf, Österreich
|
Fliegende Blätter

Das humoristisch-satirische, reich illustrierte Wochenblatt "Fliegende Blätter" erschien von
1845 bis 1944 in München in einem wöchentlichen Turnus. Als gleichermaßen künstlerisch
wie drucktechnisch bedeutsam gelten die "Fliegenden Blätter" wegen der hohen Qualität
ihrer Gestaltung. Der Verlag sorgte durch die Schulung seiner Stecher dafür, dass die Drucke
direkt vom Holzstock - erst ab 1885 im galvanischen Verfahren - höchste Detailtreue erreichten.
Die Illustrationen in den fliegenden Blättern stammen von namhaften Künstlern wie z.B.
Wilhelm Busch, Carl Spitzweg, Moritz v. Schwind, Gustav Adolf Closs, Hans Kaufmann,
Adolf Oberländer, E. Harburger und René Reinicke.
Hundert Jahre deutsche Geschichte: 200 Bände, über 5.000 Nummern, über 90.000 Seiten.
Die Fliegenden Blätter sind ein einzigartiges Werk aus dem 19. und 20. Jahrhundert, das über
Politik ebenso detailliert berichtet wie über Kultur und Gesellschaft, ein unerschöpfliches
Panoptikum und Kaleidoskop der Zeit, von Metternich über Wilhelm II. bis zum Zusammenbruch
des Dritten Reiches (Danke an den unbekannten Urheber dieser im Web allgegenwärtigen und
treffend formulierten Beschreibung der Fliegenden Blätter).
Digitalisierung der Fliegenden Blätter
Die Digitalisierung von reich bebilderter Frakturschrift-Literatur ist eine technische Herausforderung,
deshalb wird üblicherweise die
Faksimile-Reproduktion gewählt,
also eine originalgetreue Kopie in Form einer Bilddatei.
Eine Texterkennung mittels
OCR-Digitalisierung
ist aufwändig, kann aber einen erheblichen Mehrwert bieten. Insbesonders die bei der OCR-Digitalisierung
resultierende saubere Trennung zwischen Textkorpus und Bildmaterial ist ein wichtiger Aspekt:
-
Semantische Perspektive
Der Textkorpus steht unmittelbar für weiterführende semantische Anwendungen zur Verfügung, sei es
Textmining
(Worthäufigkeit, Kookkurrenz ...) oder Bedeutungsanalyse und Klassifikation des Inhaltes
(Vektorraum-Modelle,
SVM).
Darüber hinaus bietet der Textkorpus die Möglichkeit, den Sprachwandel im Laufe der Zeit zu erkennen
und den satirischen Themenfokkus, der ja ein Spiegel der damaligen Zeit ist, zu analysieren:
Was hat die Menschen damals bewegt - und was war damals (noch) kein Thema?
Im Jahr 1850 gibt es zum Beispiel keine Radfahrer-Witze, ein indirekter Hinweis darauf,
dass das Fahrrad zu dieser Zeit noch nicht in Verwendung war.
Auch das isolierte Bildmaterial kann durch Metadaten beschrieben und damit "aufgewertet" werden
(bekannterweise ist der Slogan "ein Bild sagt mehr als tausend Worte" für Suchmaschinen nicht gültig);
-
Qualitative Perspektive
Der Text steht nun mittels TrueType-Font für hochqualitative Druckergebnisse zur Verfügung, und zwar
wahlweise in originaler Frakturschrift (siehe PDF-Version) oder in "lesefreundlicher" Antiqua/Grotesk
(siehe Web-Version). Das isolierte Bildmaterial kann digital bearbeitet werden (Neutralisierung von
Hintergrundfarbe oder Verschmutzung), ohne dass die Textlesbarkeit beeinträchtigt wird;
-
Präsentationsvielfalt
Text und Bild können je nach Bedarf unterschiedlich präsentiert werden: zum Beispiel als hochqualitativer
Druck, als navigierbare Webseite, oder als Ensemble mit gemeinsamen thematischem
Kontext (z. B. Humor, Zeitgeschichte, Lyrik ...)
Der Digitalisierungsvorgang ist, wie bereits erwähnt, aufwändig: Es soll ja sowohl das Original-Erscheinungsbild
mit den vielen Layout-Finessen für eine Druckversion konserviert werden, wie auch eine inhaltliche Erschließung
für semantikbasierende Repräsentationen (z. B. Topicmaps) durchgeführt werden. Ausgehend von Seitenscans
(Faksimiles) wird der Text mittels OCR-Erkennung erfaßt, wobei die einzelnen Abbildungen vorher extrahiert und
als hochauflösende Grafiken (150 dpi) abgespeichert wurden. Die manuelle Weiterbearbeitung, bestehend aus
Textfehler-Korrektur, Bildbearbeitung, Metadaten-Anreicherung und Layout-Rekonstruktion, ist ein mehrstufiger
Arbeitsprozess, der sich kaum automatisieren lässt. Details dazu finden sich in den nachfolgenden Kapiteln.
Für die Original-Rekonstruktion der einzelnen Bände in Frakturschrift wurde ein eigener Truetype-Font
(FB-Fraktur) entwickelt, der alle Ligaturen und Sonderzeichen der Frakturschrift enthält und durch pragmatische
Zeichenbelegung sowohl Autorentätigkeit wie auch OCR-Digitalisierung unterstützt. Dieser Font steht als Download
zur Verfügung, Details dazu siehe im Kapitel Frakturfont.
Lesewarnungen *
Ein sensibles Thema ist Rassismus und Antisemitismus in der damaligen Satire, mit dem der Leser
der Fliegenden Blätter konfrontiert wird. In der Web-Version der Fliegenden Blätter sind solche Beiträge
mit einer Lesewarnung markiert und können somit vermieden werden.
Leseempfehlungen *
Im Navigationsmenü finden sich Leseempfehlungen zu einzelnen Themen. Natürlich handelt es sich dabei um
subjektive, aber keineswegs spontane Empfehlungen - zumindest sind es Empfehlungen zu Themen, die auch
beim vierten Kontroll-Lesen noch immer für interessant oder gefällig befunden wurden. Unter Anderem künstlerisch
anspruchsvolle Abbildungen, genußvolle "alterthümliche" Rethorik und Paradebeispiele zur scheinbar zeitlosen
Bürokratie und Nörgelei.
Unter den Empfehlungen finden sich aber auch echte Fundstücke, die bei der Metadaten-Erstellung "entdeckt"
wurden. Zum Beispiel unbekannte Karikaturen von Carl Spitzweg, der damals unter einem Pseudonym für die
Fliegenden Blätter arbeitete, oder der satirische Vorschlag, das Mittelmeer durch einen Staudamm bei Gibraltar
abzusenken (siehe "Pacification Europas", Band 10, Heft 219) - eine Idee, die vom deutschen Architekten
Hermann Sörgel 70 Jahre später aufgegriffen wurde
(siehe Atlantropa).
Motivation und Copyright
Dieses experimentelle Digitalisierungsprojekt ist eine Privatinitiative, also weder beauftragt noch gefördert, und verfolgt
keinen kommerziellen Zweck. Die Motivation zu diesem Projekt findet sich im Gefallen an alter Literatur, Satire und Kunst
sowie im technischen Interesse des Initiators an Metasprachen (XML), semantischen Anwendungen (Topicmaps)
und Retrodigitalisierung.
Für die im Rahmen der OCR-Digitalisierung entstandenen Ergebnisse, also insbesonders
- der fehlerkorrigierte Textkorpus,
- die semantikbasierende Aufbereitung als Topicmaps,
- und die Rekonstruktion des Original-Erscheinungsbildes
in Form von PDF-Dokumenten
gilt im Sinne des Copyrights der erheblicher Aufwand bei der Erstellung als schutzwürdige Leistung. Diese Ergebnisse
werden unter folgender Creative Commons Lizenz zur Verfügung gestellt.
© retrodig.a7111.com
Weiter mit Frakturfont, OCR-Digitalisierung, Layout-Rekonstruktion
und Web-Version (Topicmaps).
Frakturfont
Für Fraktur-Fonts gibt es keinen verbindlichen Standard zur Zeichenbelegung. Somit findet sich
am Markt ein Wildwuchs an verschiedenen Fonts mit inkompatibler Zeichenbelegungen für die
Sonderzeichen ( Ligaturen,
langes s usw.).
Ursache für dieses Dilemma ist das Desinteresse der ISO-Standardisierungsbehörde und des
Unicode-Konsortiums an dieser Thematik, da es sich bei der Frakturschrift ja nur um eine Font-Variante
handelt (so wie Arial oder Times). Der ISO-Zeichensatz 10646
( Unicode)
bietet zwar Platz für über 60.000 Zeichen und standardisiert unter anderem antike Schriften wie z. B.
Ogham (eine antike Keilschrift),
unterstützt aber nicht die speziellen Eigenheiten der Frakturschrift.
Schade, denn über hundert Jahre deutschsprachigen Kulturgutes wurde in Frakturschrift publiziert,
darunter wissenschaftliche Themen, die noch heute in aktuellen Arbeiten zitiert werden, aber im Original nicht
mehr erhältlich sind (Stichwort "Vergriffene Literatur"). Die originalgetreue, digitale Reproduktion dieser Werke
stellt Ansprüche an die verwendeten Zeichensätze, die von kaum einem erhältliche Fraktur-Font erfüllt werden.
Grundsätzlich ist die Fraktur als Alternativ-Schrift mit gleichem Zeichensatz wie eine lateinischen Schrift zu sehen,
wie z. B. dem Arial-Font. Das Problem sind die für Fraktur wichtigen Sonderzeichen, das lange s und die
"verschmolzenen" Ligaturen ch, ck und tz, die nicht durch Zeichenpaare dargestellt werden können.
Daher hilft es nicht, wenn Frakturzeichen in irregulärer Anordnung als mathematische Symbole in den erweiterten
Unicode-Zeichensatz aufgenommen werden (Multilingual Plane 1), oder wenn einige Ligaturzeichen irgendwo
verstreut in der Basic Multilingual Plane vorhanden sind. Auch die in Unicode vorgesehene Möglichkeit,
mit "zero width joiner-Zeichen" Ligaturen zu erzwingen, schlägt in der Praxis fehl.
Zu fordern wäre eine pragmatische Lösung, die sowohl Autorentätigkeit wie auch Digitalisierungskonzepte unterstützt,
das heißt, dass wichtige Fraktur-Zusatzzeichen direkt über die Tastatur erreichbar sein sollten, und das alle Ligaturen
als Sonderzeichen im Font vorhanden sein sollten. Ein für die Digitalisierung der "Fliegende Blätter" erstellte Truetype
Frakturfont "FB-Fraktur", der für nichtkommerzielle Zwecke frei als
 Download Download
zur Verfügung steht, bietet in diesem Sinne Unterstützung, im Detail:

- alle Zeichen des lateinischen Alphabets und auch alle Umlaute und Sonderzeichen finden sich an
gewohnter Stelle im Zeichensatz. Darüber hinaus sind auch alle diakritischen Kombinationszeichen des
westeuropäischen Zeichensatzes ISO-8859-1 enthalten;
- das häufig vorkommende Lange-s ist als normales s kodiert, für das eher seltene Endsilben-s wird das
Backslash-Zeichen ( \ ) verwendet, das sich auf der ß-Taste befindet und somit leicht merkbar und zugänglich ist;
- die echten Ligaturen ch, ck und tz sind über die eckigen Klammern [ ] und dem senkrechten Strich |
direkt erreichbar, womit ebenfalls die Autorentätigkeit erheblich erleichtert wird;
- die "unechten" Ligaturen ff, fi, fl, ft, ll, si, ss, st werden durch "Kerning-Paare" nachgebildet, also durch
Zeichen-Zusammenrückung im Font (siehe nebenstehende Abbildung). Im Gegensatz zu den echten Ligaturen
ist hier der Zusammenhalt der Ligatur bei gesperrter Schrift nicht zwingend erforderlich;
- weiters sind alle Ligaturen auch als Einzelzeichen aufeinander folgend in einem Unicode-Bereich bereitgestellt,
der normalerweise für "belanglose" alphabetische Sonderzeichen vorgesehen ist (Kode-Segment FB00-FB12).
Diese Zeichen sind zwar über die Tastatur nicht direkt erreichbar, können aber in einer Textverarbeitung nachträglich
mit Suchen-Ersetzen automatisch zugeordnet werden.
Die nachfolgenden Abbildungen zeigen den Zeichensatz des Frakturfonts:
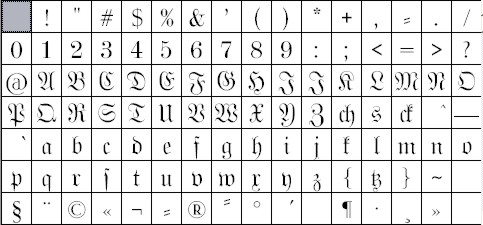
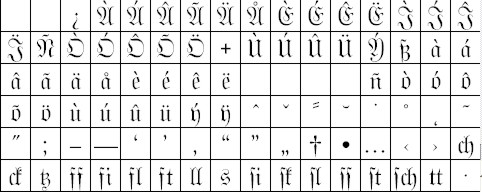
OCR-Digitalisierung
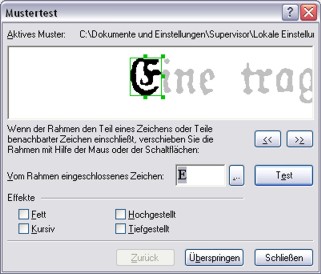
Die Texterkennung (OCR) erfolgt mittels trainierter Finereader-Software mit eher mittelmäßigem Ergebnis.
Ursache dafür ist ein bekanntes Problem bei der Frakturschrift, nämlich der grazile Duktus,
der durch altersbedingten Farbabrieb auf den Buchseiten leidet und zu ununterscheidbaren
Buchstaben führt. Speziell betroffen davon sind die Ober- und Unterstriche bei den Zeichen
u, n, m und w sowie die nahezu identen Formen von f und langem s.
Neben diesen bekannten Problemen erweist sich auch die Verwendung des integrierten Wörterbuches
als kontraproduktiv, da "alterthümliche" Worte und mundartliche Dialoge oft fehlinterpretiert werden und
zu unerwarteten Text-Metamorphosen führen. Ebenfalls nur bedingt Hilfreich für das unmittelbare Kontroll-Lesen
ist die automatische Markierung von nicht eindeutig erkannten Zeichen durch die Finereader-Software, da dies
zum "Überlesen" von Fehlern in nicht markierten Textsequenzen verleitet. Die nachfolgende Abbildung zeigt ein
typisches OCR-Ergebnis:
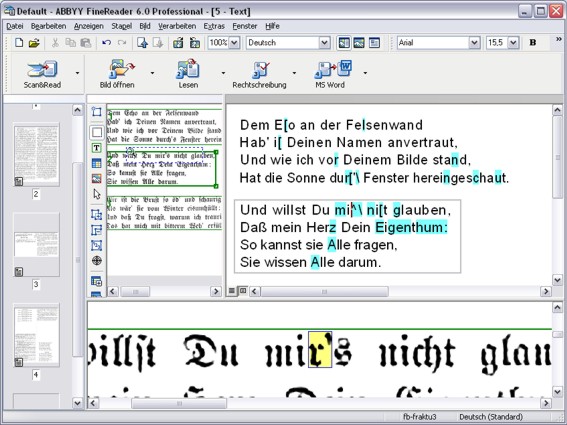
Ein mehrstufiges Konzept zur Fehlerkorrektur, das bereits beim Training der OCR-Software beginnt, ist daher
äußerst empfehlenswert. Im Rahmen des Digitalisierungsprojektes haben sich folgende Konventionen und
Vorgehenskonzepte bewährt
OCR-Training für Sonderzeichen:
- das Endsilben-s wird auf das im Font vorgesehene Code-Zeichen \ trainiert,
um von dem häufigeren langen s unterscheidbar zu sein;
- die "echten" Ligaturen ch, ck und tz werden auf die vorgesehenen Code-Zeichen [ ] |
trainiert, und nicht auf die Einzelzeichen der Ligaturen;
- alle anderen Ligaturen werden auf die entsprechenden Zeichen-Paare trainiert (ff, fi, ft ...),
soferne sie überhaupt als Ligaturen erkannt werden (unkritische Zeichenerkennung);
- die in Fraktur gleich aussehenden Großbuchstaben I und J werden auf I trainiert
und nachträglich gezielt korrigiert (Suche nach unmöglichen Vokal-Kombinationen:
Ia, Ie, Ii, Io, Iu, Iä, Iö, Iü);
- Trennstriche = werden auf - trainiert;
- Gedankenstriche werden auf _ trainiert (und erst später konvertiert)
- Anführungszeichen oben-unten werden generell auf " trainiert (und später konvertiert)
Primäre Fehlererkennung in Finereader
- alle nicht erkannten Zeichen (markiert mit ^) werden ergänzt;
- alle als Uneindeutig markierte Zeichen werden gegebenenfalls korrigiert;
- gezielte Suche nach Zeichen-Verwechslungen, insbesonders sind das:
f-s, u-n, o-v, m-w, E-C, B-V
- gezielte Suche nach Bindestrichen zwischen zusammengesetzten Wörtern,
da diese nicht von Trennstrichen unterscheidbar sind. Sie werden durch
Geviertstriche ersetzt;
- zusätzlich erfolgt ein gezieltes Markieren von fremdsprachlichen Textteilen,
die nicht in Fraktur gesetzt sind (z. B. lateinische und französische Zitate).
Dafür wird das Sonderzeichen * verwendet.
Nachbearbeitung in einer externen Textverarbeitung
Für die Nachbearbeitung wird der Finereader-Seitenstapel als Text ohne Layout exportiert.
Die Nachbearbeitung umfasst folgende grundsätzliche Aktionen:
- Automatisches Ersetzen aller nicht erkannten ch-Ligaturen durch das vorgesehene
Code-Zeichen [ . Aufgrund der hohen Häufigkeit dieser Ligatur im Text ist eine
kontrollierte Ersetzung nicht praktikabel, es kann aber davon ausgegangen werden,
dass die Buchstabenfolge c-h nur in Ligaturform auftritt. Bei der automatischen Ersetzung
ist die Groß-Kleinschreibung unbedingt zu beachten, da am Wortbeginn
keine Ligaturen vorkommen (Beispiel Christ);
- Kontrolliertes Ersetzen von nicht erkannten ck- und tz-Ligaturen mit der Such-Funktion;
- Automatisches Entfernen von aufeinanderfolgenden Mehrfach-Leerzeichen und Leerzeichen vor Satzzeichen;
- Automatisches Ersetzen von (irrtümlich erkannten) Doppel-Beistrichen und Doppel-Apostrophen mit
Anführungszeichen ";
- Suche nach unmöglichen Vokal-Kombinationen mit beginnendem I, und Korrektur auf J
(z. B. Iedermann wird auf Jedermann korrigiert);
- Konvertierung der Anführungszeichen " " in " " mittels Autoformat (z. B. in Word).
Als Ergebnis liegt nun ein "Rohtext" vor - vom Originaltext sind nur die Wort-Trennungen übernommen worden.
Dieser Rohtext dient in weiterer Folge als Ausgangsbasis für die Layout-Rekonstruktion des Originals (PDF-Version)
und für die weitere Bearbeitung als Web-Version. Dazu wird ein Duplikat des Rohtextes angelegt, in der eine
Text-Normalisierung und eine (optionale) Rechtschreibkorrektur mittels Wörterbuch erfolgt:
Text-Normalisierung und Rechtschreibkorrektur
- im Text-Duplikat werden alle Ligatur-Sonderzeichen durch ihre Zeichenfolgen ersetzt;
- alle Endsilben-s (\) werden durch normales s ersetzt;
- alle Wort-Trennzeichen werden entfernt, es verbleiben nur
Geviertstriche als Wort-Verbindungszeichen (z. B. Amts-Director);
- eine Rechtschreibkontrolle (z. B. in Word) kann nun durchgeführt werden,
wobei aber sinnvollerweise ein Benutzerwörterbuch angelegt und laufend für
"alterthümliche" Schreibweisen erweitert wird. Erkannte und korrigierte Fehler
müssen parallel dazu auch im Rohtext korrigiert werden.
- Im Rohtext können die Geviertstriche nun rückkonvertiert werden in Trennstriche,
da diese im Fraktur-Original nicht unterschieden werden
Als Ergebnis liegt nun ein größtenteils korrigierter Rohtext als Grundlage für die Layout-Rekonstruktion
und ein normalisierter Text als Grundlage für die Web-Publikation vor. Eine finale Fehlerkorrektur erfolgt
erst in diesen nachfolgenden Schritten, da sie nochmals Gelegenheit für ein aufmerksames Kontroll-Lesen bieten.
Die vor dem OCR-Vorgang extrahierten Grafiken werden mittels Bildbearbeitung gesäubert, wobei im Wesentlichen
die Seiten-Hintergrundfarbe durch Aufhellung, und allfällige Flecken durch Retuschieren entfernt werden. Die Grafiken
stehen nun ebenfalls für die nachfolgenden Schritte zur Verfügung.
Layout-Rekonstruktion (PDF-Druckversion)
Für die Layout-Rekonstruktion wird eine Word-Dokumentvorlage verwendet, die den Frakturfont als
Standardschrift und alle erforderlichen Formate, individuelle Kopfzeilen, Seitenzahlen-Generator und
das Titelseiten-Logo (Fliegende Blätter) vordefiniert enthält. Die Layout-Rekonstruktion umfasst im
Detail folgende Aktionen:
- der Rohtext wird schrittweise in die vorbereiteten Spalten eingefügt - bei wechselnden Spaltenformaten
ist dazu innerhalb der Seiten ein Abschnittswechsel erforderlich. Die Standard-Formatierung liefert dabei
die entsprechenden Absatz-Einrückungen;
- das Bildmaterial wird an entsprechender Position eingefügt, normalerweise spaltenzentriert,
in seltenen Fällen ist eine spaltenüberschreitende absolute Positionierung erforderlich;
- Titeln, Subtiteln und Fußnoten werden die entsprechende Formatierung zugewiesen;
- die Kopfzeile wird mit den entsprechenden Seitentiteln befüllt;
- alle mit * markierten fremdsprachlichen Textteile (Zitate) werden in einer passenden Antiqua-Schrift formatiert;
- abschließend erfolgt eine Kontrolle, ob alle Worttrennungen korrekt am Spaltenrand auftreten
und eine allfällige Korrektur des Textflusses.
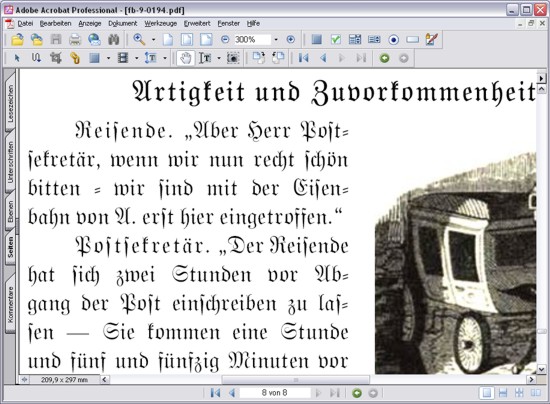
Als Ergebnis steht ein Word-Dokument für die PDF-Produktion zur Verfügung, das im Wesentlichen dem Original-
Erscheinungsbild entspricht und einen hochqualitativen Ausdruck erlaubt (siehe nachfolgende Abbildung). Durch
die Einbettung des Frakturfonts in das PDF-Dokument kann es zu einer kurzen Verzögerung beim Öffnen des
Dokumentes kommen (bis sich der Font temporär installiert hat). Während dieser Verzögerung wird der Text
in einer Standardschrift (Arial) angezeigt.
Der ursprüngliche Charme alter, vergilbter und abgegriffener Bücher geht dabei natürlich verloren,
die Konservierung solcher Impressionen ist aber nicht Zielsetzung des Projektes.
Web-Version (Topicmap)
Der normalisierte und praktisch unformatierte Text dient als Grundlage für die Aufbereitung als Web-Publikation.
Bei der Aufbereitung und Publikation von knapp 200 Bänden mit über 5.000 Einzelheften (90.000 Seiten) wird
natürlich in erster Linie an die Verwendung eines Content Management System (CMS) gedacht. Bei allen Vorteilen,
die eine CMS-Lösung bietet, ist ein gravierender Nachteil hinderlich: die Abhängigkeit von propriätären Systemen,
die weder untereinander noch zu anderen Dokumentstandards kompatibel sind. Als Alternative bietet sich das
Datenaustauschformat XML
an, und in weiterer Folge der auf XML basierende Dokumentstandard
XML Topic Maps (ISO 13250),
der eigentlich für die Beschreibung von Wissensressourcen (Wissenslandkarte) vorgesehen ist.
Warum XML?
Im Vergleich zu HTML sind XML-Dokumente extrem kompakt und für Autorentätigkeit ideal geeignet, da sie keine
Layout-Konstrukte enthalten. Das Layout für die Anzeige von XML-Dokumenten wird durch ein XSLT-Stylesheet beigestellt,
das im Gegensatz zu normalen CSS-Styles auch komplexe Funktionalität beinhalten kann. Die Eleganz der XML-Kodierung
ist bei den einzelnen Heften in der Web-Darstellung am Quellkode erkennbar (Rechte Maustaste - Quellkode anzeigen).
Siehe dazu auch XML Grundlagen.
Warum XML Topic Maps?
Bei der Suche nach einem geeigneten Dokumentstandard wird ein Pessimist vermutlich sagen, man hat nur die
Wahl zwischen Pest und Cholera, während ein Optimist das Problem gelassen sieht: egal welcher Dokumentstandard,
alle xml-basierenden Standards sind untereinander konvertierbar, somit ist es egal, welchen man wählt.
Im Wesentlichen stehen Standards wie
DocBook,
DITA (Darwin Information Typing Architecture),
TEI (Text Encoding Initiative),
DTBook (ePub)
zur Auswahl. Diese Standards haben neben XML als grundlegendes Sprachwerkzeug eine weitere Gemeinsamkeit:
sie fordern vom Autor einen hohen Tribut, der in Form formaler Metadaten zu erbringen ist, und damit verbunden natürlich
einen erheblichen Lernaufwand für die Beherrschung des Vokabulars. Die Alternative zu diesen mächtigen Standards ist
ein selbsterfundenes, maßgeschneidertes XML-Vokabular, das allerdings niemand sonst auf der Welt verwenden wird.
Zwischen diesen beiden Alternativen liegt ein interessanter und zukunftsorientierter Ansatz: die Verwendung eines
standardisierten, semantiknutzenden Vokabulars, zum Beispiel XML Topic Maps. Mit knapp 20 Strukturelementen,
von denen in der Praxis weniger als zehn für die Autorentätigkeit reichen, ist dieser Standard praktisch ohne Lernaufwand
beherrschbar. Das Grundprinzip dieses für Wissensrepräsentationen bzw. Wissenslandkarten vorgesehenen Standards ist einfach:
- Topics etablieren Themen oder Begriffe, die man näher beschreiben will
- Associations verknüpfen die Topics untereinander zu einem hierarchischen oder logischen Netzwerk
- Occurrences verweisen auf Ressourcen im Web, die passende Informationen zu den Topics enthalten
Das TAO, also die Weisheit und Mächtigkeit von Topics, Associations und Occurrences liegt in der Semantik, die von diesen
Strukturelementen gefordert und genutzt wird. Mehr zu diesem Thema siehe
Einführung in semantikbasierende Anwendungen
Für die Aufbereitung der Fliegenden Blätter wird die Flexibilität des Topicmap-Konzepts genutzt. Jeweils ein Heft der
Fliegenden Blätter wird durch eine Topicmap beschrieben, und jeder Heftbeitrag durch ein Topic. Statt als Wissenslandkarte
über verteilte Wissensressourcen zu schweben, enthält die Topicmap den kompletten Inhalt des Heftes in Form strukturierter
und typisierter Occurrences, in denen der Lesetext direkt eingebettet und mit dem externen Bildmaterial verknüpft ist.
Eine hierarchisches Struktur der Topicmap, wie zum Beispiel bei einem Buch mit Kapiteln und Unterkapiteln, ist nicht erforderlich,
da alle Beiträge eines Heftes gleichrangig sind. Eine strikte Namenskonvention und eindeutige Identifikatoren stellen sicher,
dass die einzelnen Hefte konfliktfrei zu einem übergeordneten Jahrgangsband zusammengefasst werden können.
Das streng formalen Topicmap Vokabular wird durch eine zulässige Erweiterung mit HTML-Elementen an
die Autorenbedürfnisse angepasst. Diese Erweiterung ist minimal und besteht aus folgenden Elementen:
- Bold-Element (b) für Fettdruck im Text;
- Italic-Element (i) für Kursivschrift;
- Emphasised-Element (em) für gesperrt gesetzte Texte;
- Preformated-Element (pre) für die Wiedergabe von Verszeilen bei Lyrik-Themen;
- und dem Paragraph-Element mit den Attributen align und style für die gezielte
Positionierung einzelner Textabschnitte, zum Beispiel wenn Text über Abbildungen gelegt werden muss.
Semantische Anreicherung und inhaltliche Erschließung
Jedes Thema eines Heftes wird einem Topic zugewiesen, das jeweils über eine Instanz-Beziehung mit einer der
vorgesehenen Kategorien "Erzählung", "Lyrik", "Sagenwelt", "Satire", "Humor", "Zeitgeist" oder "Sonstiges" verknüpft ist.
Diese Trivial-Taxonomie wird durch einen Genre-Katalog ergänzt und erlaubt damit eine inhaltliche Erschließung des
Text- und Bildmaterials. Der Genre-Katalog ist pragmatisch und in Hinblick auf den satirischen Inhalt maßgeschneidert.
Zum Beispiel findet sich unter "Gesellschaft" das oft vorkommende Thema "Schule" - nicht aber Universität, da in der
Satire wirre Gelehrte und schlagende Studenten als "Akteure" die akademischen Themen dominieren, und das hehre
Universitätsgeschehen nicht im Mittelpunkt steht. Folgende Genres sind zur Zeit vorgesehen:
- Gesellschaft:
Hofe Adel Landleben Stadtleben Berufsleben Wirtshaus Schule
Kirche Ehe Familie Voelker
- Staatswesen:
Monarchie Politik Buerokratie Exekutive Gericht Militaer
Krieg Revolution
- Lebenssituation:
Armut Reichtum Alter Krankheit Tod Leid Gefahr Glueck Pech
Erniedrigung Belaestigung Bestrafung
- Akteure:
Bedienstete Parvenue Studenten Gelehrte Kuenstler Offiziere
Bettler Gauner Gaukler Frauen Kinder Tiere
- Aktivitaeten:
Reise Sommerfrische Abenteuer Jagd Streit Duell Raufhandel Untat
Heirat Flirt Untreue Vergnuegen
- Handlungsmotive:
Liebe Freundschaft Bosheit Gutherzigkeit Faulheit Weisheit Dummheit
Nationalstolz Submission
- Themen:
Geschichte Fortschritt Kultur Kunst Mode Technik Verkehr
Sport Aphorismus
Die Kategorien sind teilweise fließend. Wenn bei Prosa-Texten der literarische Aspekt überwiegt, ist es eine Erzählung
oder humorvolle Satire - wenn Tagespolitik und Zeitgeschehen dominieren, ist es die Kategorie Zeitgeist. Eine ähnliche
Abwägung findet bei Humor statt - hier finden sich "zeitlose" Witze und Karikaturen - wenn aber das Zeitgeschehen im
Mittelpunkt steht, ist es die Kategorie Zeitgeist. Die Kategorie "Lyrik" umfasst im Wesentlichen alle Beiträge in Versformen,
und die abschließende Kategorie "Sonstiges" fokkusiert auf den Bildungs- und Informationsaspekt, also Aphorismen,
Reiseberichte, Weltgeschehen, Fortschritt und Visionäres.
Kategorien und Genres bilden hier ein semantisches Gerüst, das den Leser bei der Zuordnung der Beiträge unterstützt.
Idealerweise werden die in Kategorie und Genres verwendeten Begriffe wie Armut, Reichtum, Alter usw. irgendwann in Zukunft
ebenfalls durch Topics formal beschrieben, in Form übergeordneter
Ontologien.
Das wäre der nächste wichtige Schritt in Richtung eines Semantic Web, also einem Web, das von Mensch und Maschine
(in Form von Software Agenten)
gleichermaßen genutzt werden kann.
|
